 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3d Plane Detection
3D plane detection is the process of identifying and localizing planes in 3D point clouds or scenes.
Papers and Code
On the Role of Rotation Equivariance in Monocular 3D Human Pose Estimation
Jan 20, 2026Estimating 3D from 2D is one of the central tasks in computer vision. In this work, we consider the monocular setting, i.e. single-view input, for 3D human pose estimation (HPE). Here, the task is to predict a 3D point set of human skeletal joints from a single 2D input image. While by definition this is an ill-posed problem, recent work has presented methods that solve it with up to several-centimetre error. Typically, these methods employ a two-step approach, where the first step is to detect the 2D skeletal joints in the input image, followed by the step of 2D-to-3D lifting. We find that common lifting models fail when encountering a rotated input. We argue that learning a single human pose along with its in-plane rotations is considerably easier and more geometrically grounded than directly learning a point-to-point mapping. Furthermore, our intuition is that endowing the model with the notion of rotation equivariance without explicitly constraining its parameter space should lead to a more straightforward learning process than one with equivariance by design. Utilising the common HPE benchmarks, we confirm that the 2D rotation equivariance per se improves the model performance on human poses akin to rotations in the image plane, and can be efficiently and straightforwardly learned by augmentation, outperforming state-of-the-art equivariant-by-design methods.
3D-RE-GEN: 3D Reconstruction of Indoor Scenes with a Generative Framework
Dec 19, 2025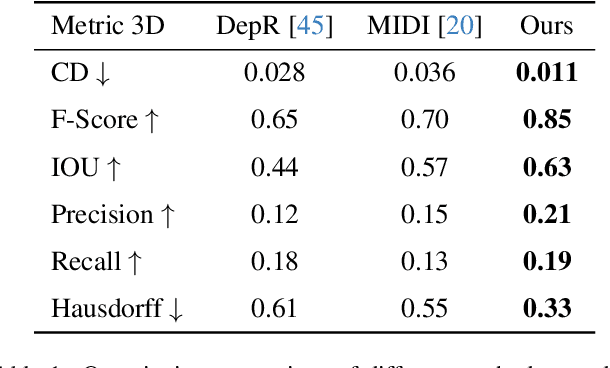
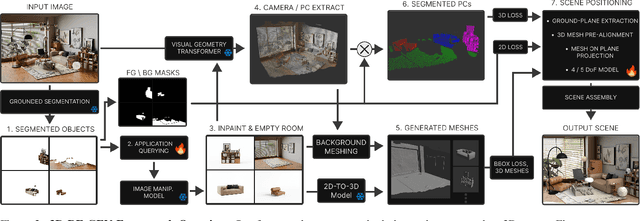
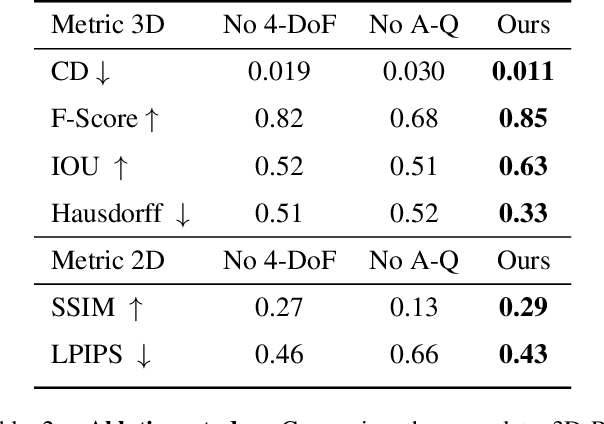
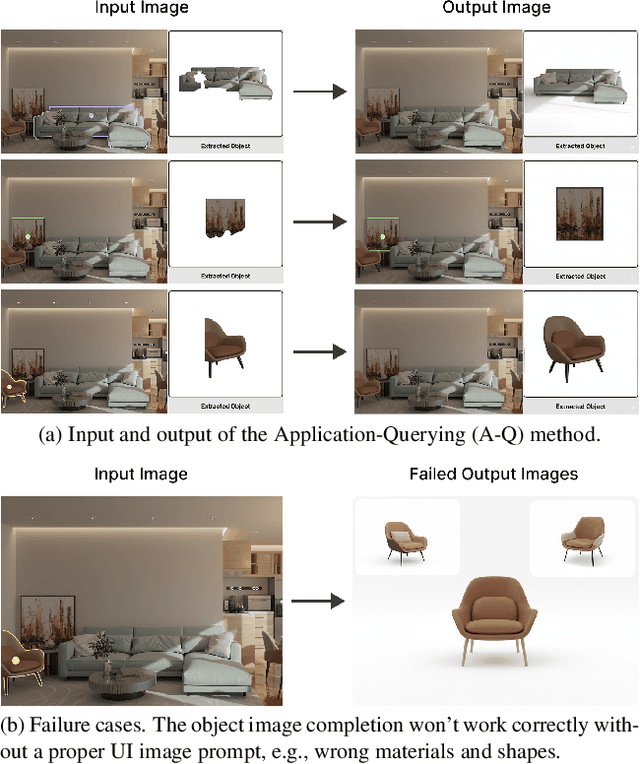
Recent advances in 3D scene generation produce visually appealing output, but current representations hinder artists' workflows that require modifiable 3D textured mesh scenes for visual effects and game development. Despite significant advances, current textured mesh scene reconstruction methods are far from artist ready, suffering from incorrect object decomposition, inaccurate spatial relationships, and missing backgrounds. We present 3D-RE-GEN, a compositional framework that reconstructs a single image into textured 3D objects and a background. We show that combining state of the art models from specific domains achieves state of the art scene reconstruction performance, addressing artists' requirements. Our reconstruction pipeline integrates models for asset detection, reconstruction, and placement, pushing certain models beyond their originally intended domains. Obtaining occluded objects is treated as an image editing task with generative models to infer and reconstruct with scene level reasoning under consistent lighting and geometry. Unlike current methods, 3D-RE-GEN generates a comprehensive background that spatially constrains objects during optimization and provides a foundation for realistic lighting and simulation tasks in visual effects and games. To obtain physically realistic layouts, we employ a novel 4-DoF differentiable optimization that aligns reconstructed objects with the estimated ground plane. 3D-RE-GEN~achieves state of the art performance in single image 3D scene reconstruction, producing coherent, modifiable scenes through compositional generation guided by precise camera recovery and spatial optimization.
Ground Plane Projection for Improved Traffic Analytics at Intersections
Nov 15, 2025Accurate turning movement counts at intersections are important for signal control, traffic management and urban planning. Computer vision systems for automatic turning movement counts typically rely on visual analysis in the image plane of an infrastructure camera. Here we explore potential advantages of back-projecting vehicles detected in one or more infrastructure cameras to the ground plane for analysis in real-world 3D coordinates. For single-camera systems we find that back-projection yields more accurate trajectory classification and turning movement counts. We further show that even higher accuracy can be achieved through weak fusion of back-projected detections from multiple cameras. These results suggeest that traffic should be analyzed on the ground plane, not the image plane
MRI Plane Orientation Detection using a Context-Aware 2.5D Model
Nov 18, 2025Humans can easily identify anatomical planes (axial, coronal, and sagittal) on a 2D MRI slice, but automated systems struggle with this task. Missing plane orientation metadata can complicate analysis, increase domain shift when merging heterogeneous datasets, and reduce accuracy of diagnostic classifiers. This study develops a classifier that accurately generates plane orientation metadata. We adopt a 2.5D context-aware model that leverages multi-slice information to avoid ambiguity from isolated slices and enable robust feature learning. We train the 2.5D model on both 3D slice sequences and static 2D images. While our 2D reference model achieves 98.74% accuracy, our 2.5D method raises this to 99.49%, reducing errors by 60%, highlighting the importance of 2.5D context. We validate the utility of our generated metadata in a brain tumor detection task. A gated strategy selectively uses metadata-enhanced predictions based on uncertainty scores, boosting accuracy from 97.0% with an image-only model to 98.0%, reducing misdiagnoses by 33.3%. We integrate our plane orientation model into an interactive web application and provide it open-source.
USV Obstacles Detection and Tracking in Marine Environments
Nov 11, 2025Developing a robust and effective obstacle detection and tracking system for Unmanned Surface Vehicle (USV) at marine environments is a challenging task. Research efforts have been made in this area during the past years by GRAAL lab at the university of Genova that resulted in a methodology for detecting and tracking obstacles on the image plane and, then, locating them in the 3D LiDAR point cloud. In this work, we continue on the developed system by, firstly, evaluating its performance on recently published marine datasets. Then, we integrate the different blocks of the system on ROS platform where we could test it in real-time on synchronized LiDAR and camera data collected in various marine conditions available in the MIT marine datasets. We present a thorough experimental analysis of the results obtained using two approaches; one that uses sensor fusion between the camera and LiDAR to detect and track the obstacles and the other uses only the LiDAR point cloud for the detection and tracking. In the end, we propose a hybrid approach that merges the advantages of both approaches to build an informative obstacles map of the surrounding environment to the USV.
SPAN: Spatial-Projection Alignment for Monocular 3D Object Detection
Nov 10, 2025Existing monocular 3D detectors typically tame the pronounced nonlinear regression of 3D bounding box through decoupled prediction paradigm, which employs multiple branches to estimate geometric center, depth, dimensions, and rotation angle separately. Although this decoupling strategy simplifies the learning process, it inherently ignores the geometric collaborative constraints between different attributes, resulting in the lack of geometric consistency prior, thereby leading to suboptimal performance. To address this issue, we propose novel Spatial-Projection Alignment (SPAN) with two pivotal components: (i). Spatial Point Alignment enforces an explicit global spatial constraint between the predicted and ground-truth 3D bounding boxes, thereby rectifying spatial drift caused by decoupled attribute regression. (ii). 3D-2D Projection Alignment ensures that the projected 3D box is aligned tightly within its corresponding 2D detection bounding box on the image plane, mitigating projection misalignment overlooked in previous works. To ensure training stability, we further introduce a Hierarchical Task Learning strategy that progressively incorporates spatial-projection alignment as 3D attribute predictions refine, preventing early stage error propagation across attributes. Extensive experiments demonstrate that the proposed method can be easily integrated into any established monocular 3D detector and delivers significant performance improvements.
Robust Alignment of the Human Embryo in 3D Ultrasound using PCA and an Ensemble of Heuristic, Atlas-based and Learning-based Classifiers Evaluated on the Rotterdam Periconceptional Cohort
Nov 05, 2025Standardized alignment of the embryo in three-dimensional (3D) ultrasound images aids prenatal growth monitoring by facilitating standard plane detection, improving visualization of landmarks and accentuating differences between different scans. In this work, we propose an automated method for standardizing this alignment. Given a segmentation mask of the embryo, Principal Component Analysis (PCA) is applied to the mask extracting the embryo's principal axes, from which four candidate orientations are derived. The candidate in standard orientation is selected using one of three strategies: a heuristic based on Pearson's correlation assessing shape, image matching to an atlas through normalized cross-correlation, and a Random Forest classifier. We tested our method on 2166 images longitudinally acquired 3D ultrasound scans from 1043 pregnancies from the Rotterdam Periconceptional Cohort, ranging from 7+0 to 12+6 weeks of gestational age. In 99.0% of images, PCA correctly extracted the principal axes of the embryo. The correct candidate was selected by the Pearson Heuristic, Atlas-based and Random Forest in 97.4%, 95.8%, and 98.4% of images, respectively. A Majority Vote of these selection methods resulted in an accuracy of 98.5%. The high accuracy of this pipeline enables consistent embryonic alignment in the first trimester, enabling scalable analysis in both clinical and research settings. The code is publicly available at: https://gitlab.com/radiology/prenatal-image-analysis/pca-3d-alignment.
* Submitted version of paper accepted at International Workshop on Preterm, Perinatal and Paediatric Image Analysis 2025
Real-time Multi-Plane Segmentation Based on GPU Accelerated High-Resolution 3D Voxel Mapping for Legged Robot Locomotion
Oct 02, 2025This paper proposes a real-time multi-plane segmentation method based on GPU-accelerated high-resolution 3D voxel mapping for legged robot locomotion. Existing online planar mapping approaches struggle to balance accuracy and computational efficiency: direct depth image segmentation from specific sensors suffers from poor temporal integration, height map-based methods cannot represent complex 3D structures like overhangs, and voxel-based plane segmentation remains unexplored for real-time applications. To address these limitations, we develop a novel framework that integrates vertex-based connected component labeling with random sample consensus based plane detection and convex hull, leveraging GPU parallel computing to rapidly extract planar regions from point clouds accumulated in high-resolution 3D voxel maps. Experimental results demonstrate that the proposed method achieves fast and accurate 3D multi-plane segmentation at over 30 Hz update rate even at a resolution of 0.01 m, enabling the detected planes to be utilized in real time for locomotion tasks. Furthermore, we validate the effectiveness of our approach through experiments in both simulated environments and physical legged robot platforms, confirming robust locomotion performance when considering 3D planar structures.
Efficient 3D Perception on Embedded Systems via Interpolation-Free Tri-Plane Lifting and Volume Fusion
Sep 18, 2025Dense 3D convolutions provide high accuracy for perception but are too computationally expensive for real-time robotic systems. Existing tri-plane methods rely on 2D image features with interpolation, point-wise queries, and implicit MLPs, which makes them computationally heavy and unsuitable for embedded 3D inference. As an alternative, we propose a novel interpolation-free tri-plane lifting and volumetric fusion framework, that directly projects 3D voxels into plane features and reconstructs a feature volume through broadcast and summation. This shifts nonlinearity to 2D convolutions, reducing complexity while remaining fully parallelizable. To capture global context, we add a low-resolution volumetric branch fused with the lifted features through a lightweight integration layer, yielding a design that is both efficient and end-to-end GPU-accelerated. To validate the effectiveness of the proposed method, we conduct experiments on classification, completion, segmentation, and detection, and we map the trade-off between efficiency and accuracy across tasks. Results show that classification and completion retain or improve accuracy, while segmentation and detection trade modest drops in accuracy for significant computational savings. On-device benchmarks on an NVIDIA Jetson Orin nano confirm robust real-time throughput, demonstrating the suitability of the approach for embedded robotic perception.
RoofSeg: An edge-aware transformer-based network for end-to-end roof plane segmentation
Aug 26, 2025Roof plane segmentation is one of the key procedures for reconstructing three-dimensional (3D) building models at levels of detail (LoD) 2 and 3 from airborne light detection and ranging (LiDAR) point clouds. The majority of current approaches for roof plane segmentation rely on the manually designed or learned features followed by some specifically designed geometric clustering strategies. Because the learned features are more powerful than the manually designed features, the deep learning-based approaches usually perform better than the traditional approaches. However, the current deep learning-based approaches have three unsolved problems. The first is that most of them are not truly end-to-end, the plane segmentation results may be not optimal. The second is that the point feature discriminability near the edges is relatively low, leading to inaccurate planar edges. The third is that the planar geometric characteristics are not sufficiently considered to constrain the network training. To solve these issues, a novel edge-aware transformer-based network, named RoofSeg, is developed for segmenting roof planes from LiDAR point clouds in a truly end-to-end manner. In the RoofSeg, we leverage a transformer encoder-decoder-based framework to hierarchically predict the plane instance masks with the use of a set of learnable plane queries. To further improve the segmentation accuracy of edge regions, we also design an Edge-Aware Mask Module (EAMM) that sufficiently incorporates planar geometric prior of edges to enhance its discriminability for plane instance mask refinement. In addition, we propose an adaptive weighting strategy in the mask loss to reduce the influence of misclassified points, and also propose a new plane geometric loss to constrain the network training.